Modern-day businesses generate vast amounts of data in their operational processes. In 2027, the global big data analytics market size will exceed $100 billion, depending on the sector. Statistics show that the upward trend is quite solid, and more businesses are likely to adopt strategic big data in their digital environment.
As evident, most companies today do not have any problems with data volume. They struggle with making it usable for AI. At this stage, a successful big data strategy is about building an AI-ready data foundation that can continuously generate insights and predictions.
At Intelliarts, we approach this challenge through a structured methodology, designed to align business goals, data architecture, and AI capabilities into a single, scalable system. This playbook helps enterprises move from fragmented data initiatives to production-ready AI ecosystems.
What is a big data strategy?
A successful data strategy is what links business goals with technology solutions. You can get an insight into how the data is approached across different levels of data strategy from the infographics below.

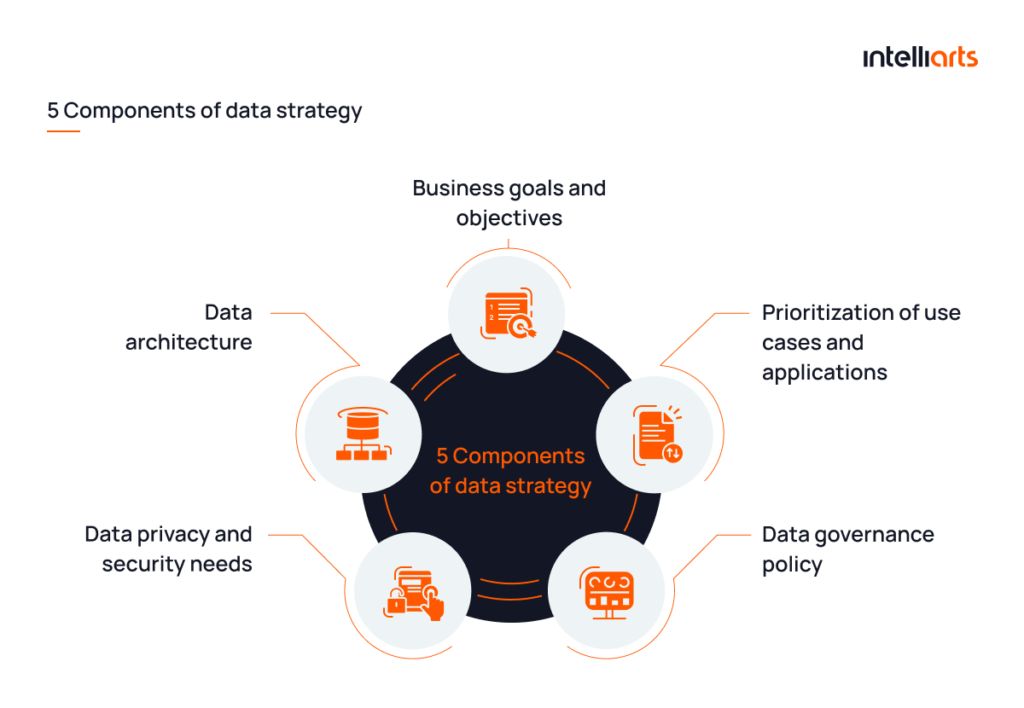
In simple terms, what is a data strategy? This is a clear plan for how an organization will collect, manage, and analyze data and derive value from it to meet specific business objectives. Based on our years of experience in machine learning and data science, Intelliarts specialists distinguish the next components of a data strategy:
#1 Business goals and objectives
Specific, measurable objectives provide a framework for what it’s intended to achieve with the data. Examples may include:
- Reducing operational costs
- Improving customer satisfaction
- Identifying new revenue streams
- Optimizing supply chain processes
- Discovering business opportunities
Setting clear goals will guide data collection, analysis, and utilization efforts.
#2 Prioritization of use cases and applications
A big data business strategy can cover an extensive range of use cases and applications, such as:
- Predictive maintenance
- Sales forecasting
- Customer segmentation
- Social media monitoring
- Workforce analytics
From our clients’ experience, we know that it’s crucial to prioritize the listed to maximize ROI. Focus first on projects that yield quick wins or solve pressing issues. Subsequent phases can tackle more complex or long-term projects.
#3 Data governance policy
A robust data governance policy ensures that data is consistent, trustworthy, and used responsibly. It outlines who has ownership of data, establishes data quality benchmarks, and details the procedures for data access and sharing.
A strong governance policy can minimize the risks of data silos, inconsistencies, and compliance issues, which can impede the successful execution of a big data strategy.
#4 Data privacy and security needs
Data privacy and security are not optional but integral to a big data strategy. Complying with regulations like HIPAA, GDPR, or CCPA is just the starting point.
A comprehensive strategy will go beyond compliance to include data encryption, regular technical audits, and incident response plans.
Failing to adequately address privacy and security concerns can result in financial penalties and reputational damage. For example, understanding the CSPM definition helps organizations strengthen their cloud environments and proactively address compliance requirements as part of a holistic data security strategy.
#5 Data architecture
A well-designed data architecture is the backbone that supports data storage, integration, and retrieval. This involves choosing between data lakes, data warehouses, or hybrid solutions based on your specific needs.
Data architecture also concerns itself with data flow, scalability, and ensuring that the technology stack aligns with both current and future business requirements.
Here’s the sum up of all 5 components:
Since the big data strategy composition is clear, let’s find out why your data strategy might fail.
Why traditional data strategies fail in 2026
Forbes informs that 95% of enterprise AI initiatives deliver zero measurable return. Most failures of AI projects owe to poor data quality, lack of data governance, and disconnected data ecosystems. At the same time, research says that only 24% of companies describe themselves as data-driven, and only 2% name data literacy among their priorities.
The root problem is architectural. Traditional data strategies were built for reporting and dashboards, and they don’t consider real-time decisioning, ML pipelines, or scalable AI systems. This results in:
- Fragmented data silos that block model training
- Inconsistent data quality that erodes trust in AI outputs
- Rigid architectures that cannot support real-time or adaptive systems
- Governance models that lag behind regulatory and security demands
In 2026, these limitations become a significant barrier to AI adoption and competitive advantage. And to move forward, organizations should shift from simple data management to AI-ready data architecture and replace static strategies with adaptive, architecture-first methodologies.
If you’re unsure where to start, think about data strategy consulting that can help you identify gaps and define a clear path forward.
The Intelliarts big data strategy framework
At Intelliarts, we treat big data strategy as an AI-readiness journey. Based on our experience delivering data platforms across industries, we’ve developed a structured data strategy framework that outlines the essential big data strategy steps for building AI-ready systems and allows companies to effectively handle complex data sets and analytics at scale.
Now when you have an understanding of what essentials are good to have from the beginning, let’s proceed with learning the composition of a big data analytics strategy.
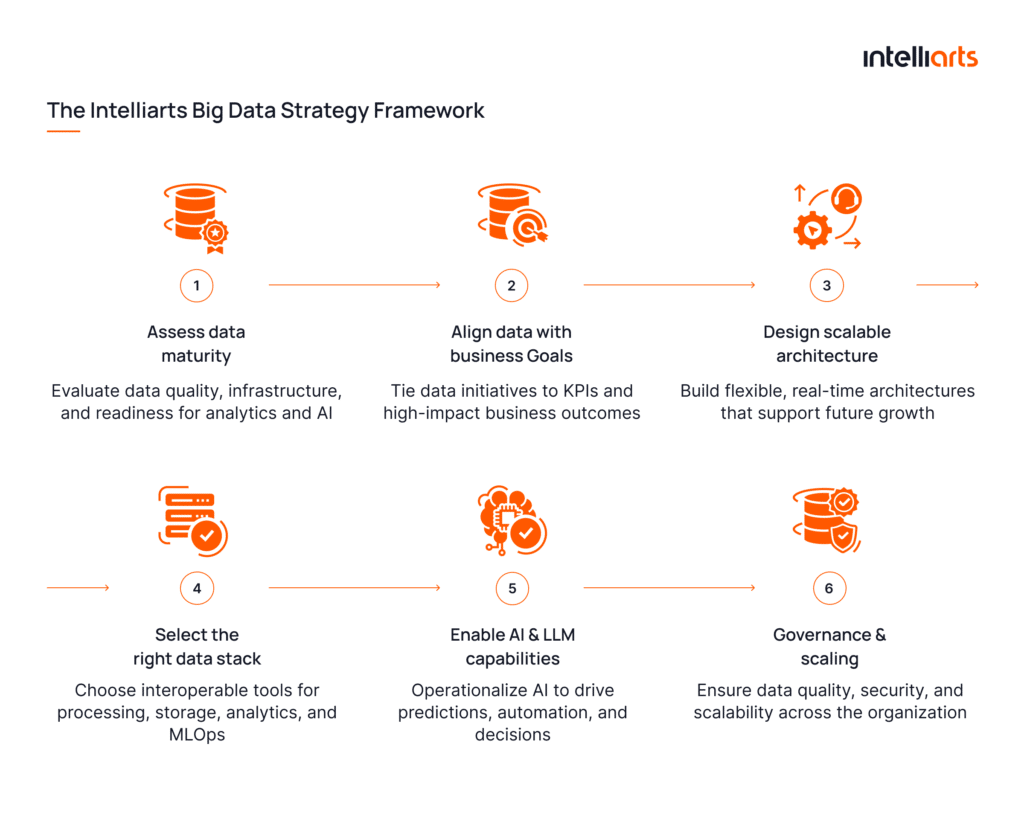
Step 1: Assess data maturity
From our experience, most organizations overestimate their data readiness. The first step is to evaluate your current data landscape, including data quality, infrastructure, accessibility, and data governance. This involves analyzing existing systems, identifying gaps, and understanding whether your data can realistically support advanced analytics or AI use cases.
Step 2: Align data with business goals
Integrating data strategy with your business strategy ensures that data initiatives contribute to the achievement of business goals. A well-defined strategy to deploy big data technology in a firm should involve reviewing business objectives, aligning data metrics with business KPIs, prioritizing data projects, and ensuring cross-departmental alignment. This integration also involves defining strategies for utilizing big data in corporate growth.
When the two strategies are well-aligned it allows for effective decision-making and a higher likelihood of success.
Step 3: Design scalable architecture
Traditional architectures are one of the biggest blockers to AI.
At Intelliarts, we design architectures that support scalability and real-time processing, as part of our data architecture strategy services. Depending on the use case, this may include data lakes, data warehouses, or hybrid models. But the key of your big data architecture is that it grants seamless data flow and future-proof infrastructure.
A well-designed architecture becomes the foundation for integrating analytics and machine learning into everyday operations further.
Step 4: Select the right data stack
From our project experience, selecting the right tools depends on your specific data needs, scalability requirements, and team capabilities. This includes data processing frameworks, storage solutions, and analytics platforms.
Consider making an effort to:
- Select appropriate analytical tools. The Intelliarts team recommends AWS SageMaker, Azure Machine Learning, H2O Driverless AI, IBM Watson Studio, DataBricks, Minitab, and Qlik AutoML.
- Leverage predictive analytics and other ML technologies like descriptive analytics, data mining, business intelligence, etc.
- Select appropriate visualization tools. Here our team usually chooses Power BI, Tableau, Grafana, and Amazon QuickSight.
- Define your data storage strategy. Decide between data lakes, warehouses, or lakehouse architectures (e.g., Databricks Lakehouse) based on data variety, latency requirements, and AI use cases.
- Standardize data processing frameworks. Use distributed processing engines like Apache Spark or Flink to handle large-scale data transformations and enable real-time pipelines.
- Plan for real-time vs batch processing. Clearly separate use cases that require streaming (e.g., fraud detection, IoT) from those suitable for batch processing (e.g., reporting, historical analysis).
- Ensure interoperability and integration. Your stack should support integration across APIs, ETL / ELT pipelines, and third-party systems to avoid data silos.
- Incorporate MLOps capabilities. We recommend using tools like MLflow, Kubeflow, or native cloud MLOps services to help manage model lifecycle, versioning, and deployment at scale.
Whether it’s cloud-based ecosystems or specialized tools, the general idea is to build a cohesive modern data stack that supports both current workloads and future AI initiatives.
You may be interested in learning more about big data value, data analytics, and machine learning in another of our blog posts.
Step 5: Enable AI & LLM capabilities
At this stage, we move to AI in production, as a key focus area in AI data strategy consulting. Without it, even the most advanced data platforms remain cost centers that produce reports instead of driving decisions and automation.
At Intelliarts, we help companies integrate machine learning pipelines, predictive analytics, and LLMs into their data ecosystems at this step. This includes setting up environments for model training, deployment, and continuous improvement.
If we sum up all our experience, data strategy best practices here include:
- Establish model success criteria upfront. From our experience, it works great to define your metric earlier, whether it’s revenue increase, cost reduction, or process time savings.
- Design for production latency requirements. Consider whether your models need real-time inference, near-real-time responses, or offline scoring. This directly impacts your system design.
- Control data and model drift. Set up monitoring to detect changes in data distribution or model performance before they impact business outcomes.
- Ensure explainability and transparency. Especially in regulated industries, models should provide interpretable outputs to support compliance and stakeholder trust.
- Design for LLM and AI integration. Include vector databases (e.g., Pinecone, Weaviate), embedding pipelines, and orchestration frameworks (like LangChain) if generative AI is part of your roadmap.
- Plan for reuse and scaling of AI assets. Treat models, pipelines, and components as reusable building blocks rather than one-off implementations.
Step 6: Governance & scaling
As systems grow, governance becomes a critical success factor.
A strong governance framework is a prerequisite for data quality, security, and compliance while also enabling controlled access across teams. This includes defining ownership, establishing data standards, and implementing monitoring processes.
Equally important is thinking about scalability. To strengthen your enterprise data strategy, make sure that your cloud data platform strategy can evolve with growing data volumes along with new use cases and changing regulatory requirements.
How to implement a big data strategy
While the Intelliarts framework explains how to build a big data strategy, the next question is how to execute it in practice. Below is a practical implementation approach we typically follow in real projects.
Timeline
A big data strategy is not a one-time initiative. Take an iterative approach for better results:
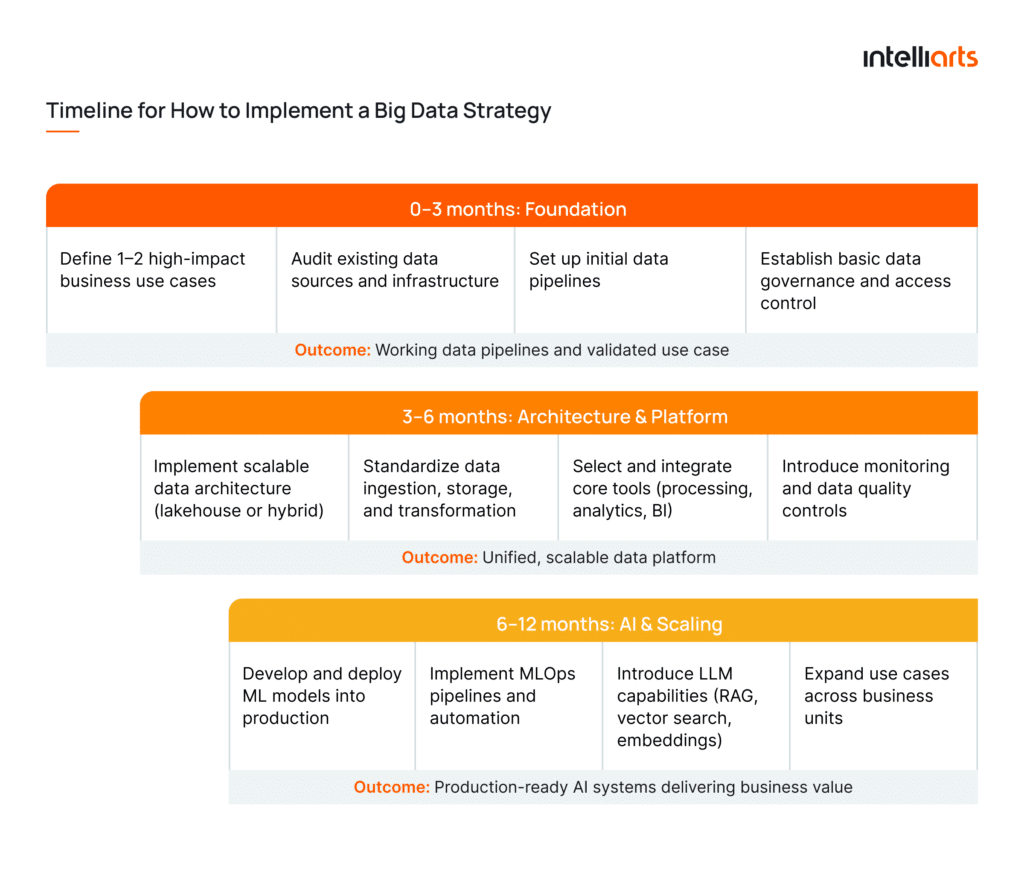
As for project time estimations, it’s worth noting that small-scale projects take about three months from start to finish. Average to large-scale projects take six months or more to complete.
Some factors affecting the duration of data strategy development and execution project are:
- Team size
- Volume and complexity of data
- Potential data issues and technical debt
- Infrastructure specificities
- The need to comply with regulatory or other specific requirements
It can be recommended to consult with a specialized agency to get accurate estimations of the potential project’s time and costs.
Team structure
Implementing a big data strategy requires the strong expertise and experience of a diverse team. The list of irreplaceable, in this project, specialists includes: data engineers, data scientists, data analysts, big data and AI architects.
Additionally, the project may also require the involvement of cloud specialists, business analysts, data governance and compliance officers, domain experts, DevOps engineers, and project managers. Big data consultancy with a potential services provider can help with obtaining more accurate information.
In smaller teams, roles may overlap. In enterprise environments, clear ownership is critical to avoid bottlenecks.
Modern data architectures explained
From our experience, choosing the wrong architecture is one of the most expensive mistakes companies make in data strategy. This is actually why many companies rely on data platform consulting. Many of our clients have invested heavily in tools, but without the right architecture in place, they struggled to scale AI initiatives or deliver real-time insights.
Below is how we approach modern data architecture 2026 in practice:
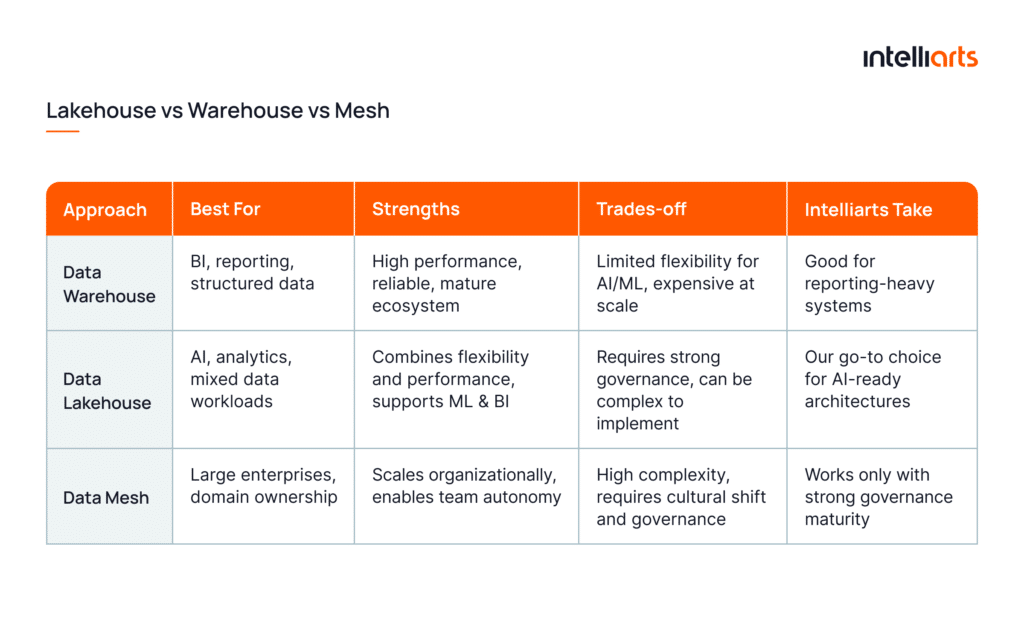
Data mesh vs data lakehouse vs data warehouse
In our projects, architecture choice always depends on data complexity, scale, and organizational structure. And it’s never trends.
- Data Warehouse works best for structured data and BI reporting, often powered by platforms like Snowflake in modern cloud environments. However, according to Deloitte, traditional warehouses struggle to support advanced analytics and AI workloads due to limited flexibility.
- Data Lakehouse is what we most commonly recommend today. It combines the flexibility of data lakes with the performance of warehouses, which makes it suitable for both analytics and machine learning. Reports show that Databricks (a well-known lakehouse architecture) grows over 55% year over year, as organizations seek unified platforms for BI and AI.
- Data Mesh is more an organizational approach than technology. It works well for enterprise data strategy where teams need ownership of their data domains. However, be aware that without strong governance, mesh adoption can lead to fragmentation, as we’ve experienced firsthand.
Pro tip: If you’re building for AI, start with a lakehouse approach and introduce mesh principles only when your organization is ready for distributed ownership.
Real-time vs batch data processing
Over 60% of organizations today are increasing investment in real-time data, yet many struggle to justify ROI due to unnecessary complexity. Based on our experience, Intelliarts ML team recommends not to overengineer your real-time systems where it’s not needed:
- Batch processing remains more cost-effective and sufficient for use cases like reporting, trend analysis, and periodic model training.
- Real-time processing works better for time-sensitive scenarios such as fraud detection, dynamic pricing, IoT, or personalized user experiences.
Somehow, companies often default to real-time because it sounds more advanced. However, the truth is that you don’t always need it, but this approach does add to complexity and cost. So better start with batch-first architecture. And introduce real-time pipelines only where speed directly drives revenue or user experience.
Streaming pipelines
Confusion also appears when it comes to streaming. At Intelliarts, we choose streaming pipelines to ensure continuous data flow and immediate insight generation. This can be especially useful in high-velocity data environments.
Typical components we implement include:
- Event streaming platforms (e.g., Apache Kafka)
- Stream processing engines (e.g., Flink, Spark Streaming)
- Real-time data ingestion and transformation layers
When we implement streaming pipelines, our ML team always does best to:
- Build resilient pipelines with retry, replay, and fault-tolerance mechanisms
- Maintain strict schema governance across streams
- Continuously monitor latency and throughput
- Avoid blending batch and streaming without clear boundaries
How big data strategy powers AI & LLM systems
As partly mentioned, your big data strategy also impacts the efficiency of AI and LLM initiatives. In short, there are 4 critical ways of how big data implementation can affect your AI and LLM systems:
1. Data availability and quality
As you know, AI systems are only as good as the data they rely on. A strong strategy ensures consistent, clean, and well-governed data pipelines. This is especially critical for data strategy for LLMs, where poor data quality leads to hallucinations and irrelevant outputs.
In practice, this includes:
- Standardized data ingestion and validation
- Data lineage and quality monitoring
- Centralized, reusable datasets
2. Scalable infrastructure for AI
AI depends on architectures that support continuous training, real-time inference, and high-load processing. All this is possible only with a solid data foundation.
3. Context for LLMs through internal data
LLMs deliver real business value only when connected to proprietary data. This requires structured pipelines for retrieval, embedding, and secure access.
Pro tip: We observed that some companies fail when they adopt LLMs, but don’t connect them to the data that actually matters.
4. AI-ready data components
Modern AI systems rely on specialized data infrastructure that must be designed upfront:
- Feature stores to standardize and reuse features across ML models
- Vector databases to enable semantic search and LLM retrieval
- RAG (retrieval-augmented generation) pipelines to combine LLMs with internal knowledge sources
- Production data pipelines to continuously feed and update AI systems
Gartner predicts that in 2026, over 80% of enterprises will have used generative AI APIs or deployed production-ready LLM applications. So this makes AI readiness a critical competitive factor, and companies need to treat data strategy as the foundation for AI.
Are you looking for a trusted provider of big data consulting services? Reach out to Intelliarts and let’s discuss cooperation opportunities!
How to choose the right data stack
When you choose your data stack, make sure you match it with data maturity and use cases. Judging from our projects, the wrong stack can bring risks like unnecessary complexity or rising costs. Vice versa, the right one leads to scalability, interoperability, and faster time to value.
To help you out, here is a data stack comparison table where you can get started. But better to take advantage of big data consulting services with professionals:
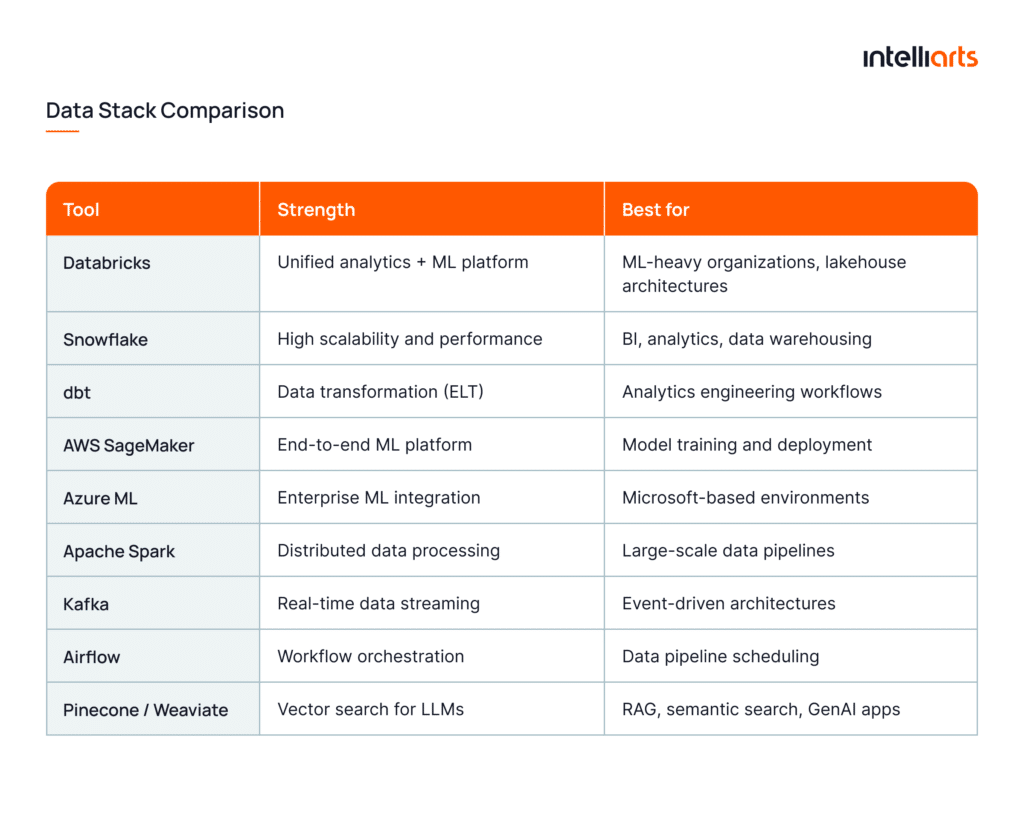
As big data experts, we can say that the real differentiator lies in how these decisions translate into business outcomes. This is actually where theory meets execution so let’s look at a few case studies to explore how all these principles work in practice.
Real-world big data strategy examples
As mentioned, we at Intelliarts have substantial experience helping our customers create a big data strategy and bring it to life. Our related big data strategy example includes the following:
DDMR data pipeline case study
Challenge: The challenge was to help collect data on Firefox and optimize the efficiency of the big data collection process. Since the company was selling clickstream data, the success of its sales department largely depended on how the business handled big data.
Solution: The solution was a browser application and an end-to-end data pipeline which included data collection, storage, processing, and delivery. The architecture was designed for high scalability and performance, enabling efficient handling of massive clickstream datasets.
Outcomes: We grew from zero to operating clusters with 2000 cores and 3700 GB of RAM. During the cooperation, our customer multiplied its annual revenue and won a base of loyal customers.
Real estate case study
Challenge: The challenge was to predict homeowners who are going to sell a house before the property is put up for sale. The company was tracking more than 1400 property and demographic data attributes and had a huge dataset with more than 60 million data records, and it was necessary to ensure the raw data was processed effectively.
Solution: The solution was the re-uploading of data to Amazon S3 data storage, completing data transformation, and establishing data processing with the help of AWS Glue. This created a reliable foundation for machine learning model development.
Outcomes: The model that can operate on the processed data can predict at least 70% of homeowners who are going to sell their houses. This result is a lot above the average in the industry.
Big data strategy readiness checklist (Downloadable)
Before investing in big data architecture or tools, or AI initiatives, it’s critical to understand one thing: are you actually ready? This checklist will help you decide.

How to use this checklist? If you answer “no” to more than 30% of these questions, your organization is not yet ready for full-scale AI adoption. Focus on closing the gaps first.
Also, don’t forget to save this checklist for later – grab it as a ready-to-use PDF for your team.
Common challenges and how to overcome them
Building a big data strategy is a challenging task by itself. So there is a lot of stumbling blocks that you’ll face on your way:
1. Poor data quality
Challenge: Inconsistent, incomplete, or unreliable data.
How to overcome: Implement data quality checks at the pipeline level. Assign data ownership and enforce standards continuously.
2. Fragmented data ecosystems
Challenge: Data silos across systems.
How to overcome: Invest in integration-first architecture (lakehouse, unified pipelines). Prioritize interoperability over adding new tools.
3. Overengineering infrastructure
Challenge: Teams build overly complex real-time or distributed systems.
How to overcome: Adopt a “start simple, scale when needed” approach. Use batch processing by default and introduce complexity only when justified by business value.
4. Governance, security, and compliance
Challenge: Regulatory requirements (GDPR, HIPAA, etc.) and security concerns slow down adoption.
How to overcome: Embed governance and security into architecture from day one, including access control, data lineage, and auditability.
5. Difficulty moving AI to Production
Challenge: Many organizations get stuck at experimentation and fail to operationalize models.
How to overcome: Implement MLOps practices early, standardize deployment processes, and integrate AI outputs into real business workflows.
Also, we advise not to try to solve everything at once. From Intelliarts experience, it works better to take an iterative approach: start with high-impact use cases and scale systematically.
Final take
A big data strategy is a comprehensive plan for a business to approach its data and build a foundation for AI.
From our experience, success doesn’t come from isolated tools or one-time initiatives. It comes from a structured approach that aligns business goals, modern architecture, and AI capabilities into a single, scalable system. This is exactly what the Intelliarts framework is all about.
Whether you’re starting from scratch or evolving an existing data ecosystem, the key is to build with AI in mind from day one. At Intelliarts, we combine over 24 years of experience with deep expertise in data engineering, analytics, and AI to bring your data project to success.
FAQ
1. What is a big data strategy?
A big data strategy is a structured approach to collecting, managing, and using data to achieve business goals.
2. How do you build a data strategy?
You build a data strategy by aligning business goals with your data, designing scalable architecture, selecting the right tools, and enabling AI use cases through governed, production-ready data pipelines.
3. What architecture is best for big data?
In our experience, a lakehouse architecture is the most practical choice for modern big data environments because it supports both scalable analytics and AI workloads. At the same time, the best option still depends on your data complexity, latency needs, and data governance requirements.